阿里云系统平台同步Paxos协议使用案例!
- 2016-04-18 12:56:50
-
2016 ATF阿里技术论坛于4月15日在清华大学举办,主旨是阐述阿里对世界创新做出的贡献。阿里巴巴集团技术委员会主席王坚,阿里巴巴集团首席技术官(CTO)张建锋(花名:行癫),阿里巴巴集团首席风险官(CRO)刘振飞(花名:振飞),蚂蚁金服首席技术官(CTO)程立(花名:鲁肃)以及来自阿里巴巴集团各部门多位技术大咖齐聚一堂,与莘莘学子分享阿里的技术梦想。
在下午的云计算与大数据论坛上,阿里云资深专家林伟(花名:伟林)带来了以《大数据计算平台的研究与实践》为主题的深度分享。林伟目前负责阿里云MaxCompute平台的架构设计,在加入阿里云之前,就职于微软总部Bing Infrastructure团队,从事大数据平台Cosmos/Scope的研发。在大数据领域研究多年的他,演讲内容非常务实,引发学生们的多次互动。
他的分享主题聚焦目前阿里云在大数据计算平台建设过程中的一些思考,以及在面对数据存储、资源调度等挑战时的解决思路和实践经验,同时对大数据计算平台建设的最新进展进行了简明的介绍。本文内容根据其演讲内容整理。
分布式文件系统
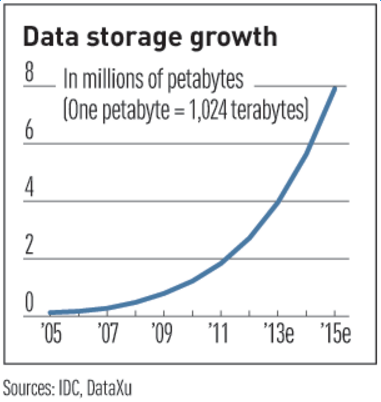
图1 数据的增长速度曲线
相关研究数据表明,我们正面临的是一个数据指数爆炸的时代,数据无时无刻不在产生,而90%的数据产生于近2年,产生的速度是非常惊人的。2011年有预测表明,2015年时数据即可达到800万PB,而阿里云的愿景是打造数据分享第一平台,帮助用户挖掘数据价值,在面对如此海量的数据、想要通过大数据平台分析其背后的巨大价值之前,首先就需要能够将数据保存下来,并且是要廉价的保留下来。这就要求一定要使用基于大规模工业流水线上生产的普通PC和SATA磁盘,打造廉价的存储系统用于存储数据。但是,由于是大规模流水线生产出来的普通硬件,一定会有相对的次品率,一块硬盘平均每年会有百分之几的出错概率。在这种情况下,如何在这个出错概率上去保证数据服务的高可用性,我们就需要依赖多副本来提高我们的容错能力。 从而能够做到我们10个九的可靠性的数据服务。
多副本
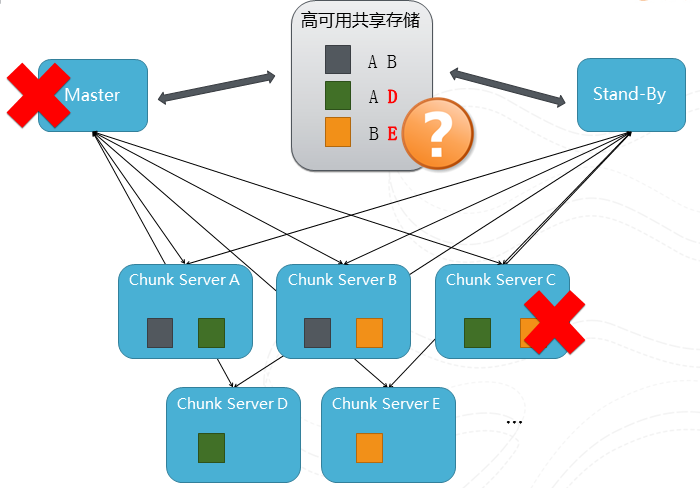
图2 一个多副本slide的过程
这张图描述了一个多副本的过程,我们有多台chunk server分布式的来保存文件,在这个例子中有灰,绿和橙色三个文件,为了简化描述,假设每个文件有2个副本(在真实系统里面副本的个数是可以控制的,根据数据的重要性、副本可以扩展到3个或多个不等)分布在不同的chunk server中。然后我们把关于副本位置的元数据保存在元数据服务器Master中,假设这个时候Chunk Server C机器坏了,但是因为每个文件至少还是有个副本在服务,所以对服务是没有影响的。不过为了保持系统的容错水平,我们及时把绿和橙色文件从ServerA和ServerB复制到D和E上从而恢复2副本的水平。但是这里还有一个问题,如果Master的机器坏了怎么办?这就相当于丢失了副本的位置信息,用户就没有办法知道各副本的分布位置,就是副本是还是安全可靠的,但是整个服务还是会停滞了。为了解决这个问题,Hadoop的方案是采用加一个stand-by的机器,当Master出错的时候,stand-by的机器将接管元数据的服务。但这个解决方案需要依赖于有个高可用的共享存储来保存元数据本身。但是我们本来就是想搭建一个高可用的存储服务,不能去依赖另外一个服务来作为保证,所以我们采用了Paxos的协议来搭建我们的元数据服务。
Paxos 高可用方案(盘古)
Paxos协议,是2013年图灵奖获得主Lamport在1989年发表的一篇论文,该论文解决了分布式系统下一致性问题。如果大家感兴趣可以去读一下论文。

图3 Leslie Lamport
(Leslie Lamport,微软研究院科学家,2013年图灵奖得主,1989发表Paxos解决了分布系统下的一致性问题)
这个协议的推演是个复杂的过程,其主要思路就是在2N+1的群体中通过协议交换信息,通过少数服从多数的方式达到整个数据的一致性。这样一来,元数据可以大家分别各自存储,不存在需要额外的高可用的共享存储。并且只要存在多数者,我们就能提供准确一致的元数据服务。
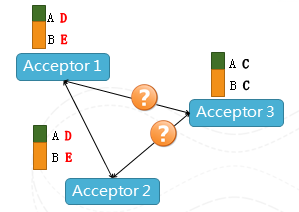
图4 场景示意
在上图中,Acceptor相当于一个仲裁者,我们可以看到Acceptor 3因为某种原因不能和Acceptor1、2联系,但是只要1、2看到是一致的元数据,服务就可以继续下去,所以不会存在单点Failure,整个系统的容错等级也是可以配置的,根据机器的环境、出错的概率、恢复的速度进行调整,最多可以容忍N台机器出错(2N+1机器组成的Paxos),并且该协议中各个请求不需要同步,都是纯异步的方式,使得整个协议不会因为某些机器的延时而造成性能的下降,在分布式系统中,这个临时性能波动是非常常见的。这个方案没有任何额外需要高可用的共享存储,就可以通过普通PC的机器环境里面来达到高可用性。
盘古分布式文件系统

图5 场景示意
刚刚讲到阿里的分布式文件系统盘古就是由保存数据多副本的大量的Chunk Server加上一个提供高可用的元数据服务的Paxos群来提供高可靠的数据服务。此外,我们还在高可靠,多租户,高性能,大规模等方面做了大量的研究和工作。比如多租户访问权限控制,流控,公平性,离线在线混布;高性能方向,比如混合存储,我们知道SSD盘存储量高、读写性能好但是贵,我们如何结合SSD的高性能,高吞吐和SATA的低沉本高密度做到一个性能上贴近SSD,但是成本贴近SATA等等。
资源调度的挑战
刚刚说了存储,数据存下来了,但是如果仅仅是存,而不是分析,那数据只是躺在系统里的垃圾。所以,数据一定要动起来。在存储的基础上去搭建一个计算平台去分析数据背后的价值,而首要解决的的就是调度的问题,如何任务能够高效调度到我们集群中的资源上去运行。其实就是把你的需求和你的资源做个Match。这么说起来很简单的问题,但是一旦规模大了、需求各异了,就会变得很难。因为我们的规模,机器负载时时刻刻都在变化,需求上也是要求各异,比如CPU/磁盘/网络等等, 运行时间,实时性要求,需求直接的关系也是各自不同的。如何在有限的时间中快速的进行bin-pack的算法,达到资源的充分使用,并同时保证实时性,公平性等等不同需求的平衡是非常挑战的。
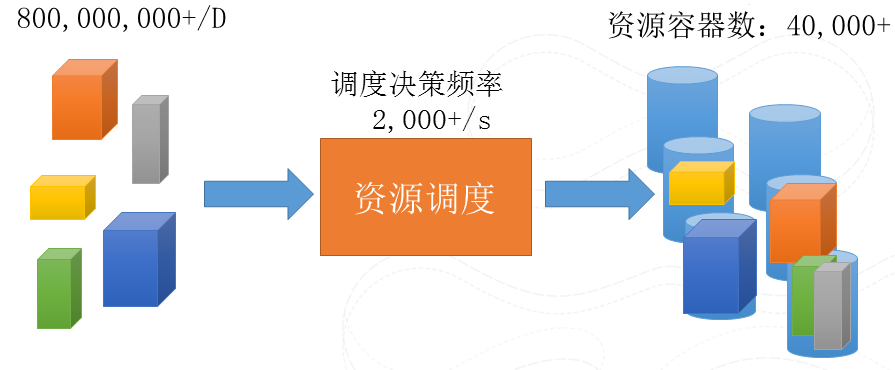
图6 待调度实例数
调动的多维目标
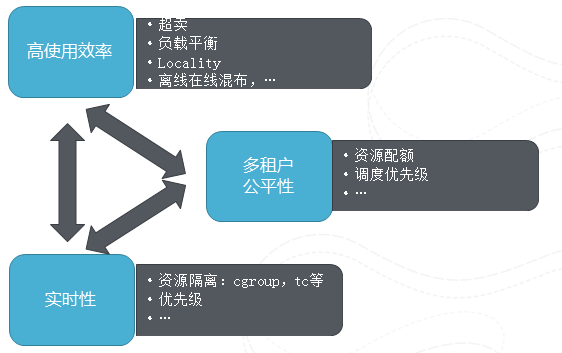
图7 调动的多维目标
这里主要展示了在调度中多个维度的目标,这些目标是相互牵扯的。比如高效率就希望尽量把机器装满,有空就塞一个任务进去,但是这样就会影响公平性,如果总是以这种方式,那么小任务、比较灵活的任务容易被执行,总能够得到机会调度,那些比较有更多要求,约束条件的任务就会被饿死,所以高可用性和公平性是有矛盾的。再举个例子,实时性就是希望预留资源从而不会出现打满的情况,但这样势必带来资源的浪费,影响使用效率。阿里云在各个维度上均做了大量的工作,比如高使用效率上,我们做了负载平衡,离线在线混布,就近执行优化,资源复用。多租户方面资源配额的管理,优先级。实时性方向,资源如何隔离等等。而要在这些看似矛盾的调度目标上做到很好一个调度系统,其本身需要基于非常详尽的运行统计和预测数据,比如资源要求的推算,机器负载的实时统计数据等等,并在这些数据帮助下及时的做出好的决策。
举一个资源复用的例子说明一下提高机器的使用效率同时保证实时性不被破坏,我们套用航空中的例子来解释。我们把用户分成几种group.:有非常重要的job,对于实时性,完成时间要求很高的用户,他们就是金卡会员,他来了我们优先让他登机,访问我们机器的资源;剩下是普通用户,需用排队享用云服务;最后一部分用户他们对完成时间没有什么要求,如果碰巧金卡会员没有来,或者使用的资源没有占满,他们就可以提前坐当前航班,但是如果来了金卡会员,他们就只能做下一班航班了。通过这种方式我们来达到资源使用和实时性要求的一种平衡。听起来似乎很简单,但是如何设计各个舱位的比例,什么时候能够允许抢占,谁抢占,抢占谁。还有每个任务的运行时间,开始时间的不同,如何分配他们到不同的航班,每个都是可以好好研究的问题,这个事情需要真正和业务、和后面的服务进行一种可适配的调整来去达到性能很好的平衡。
伏羲作业编程模型:DAG
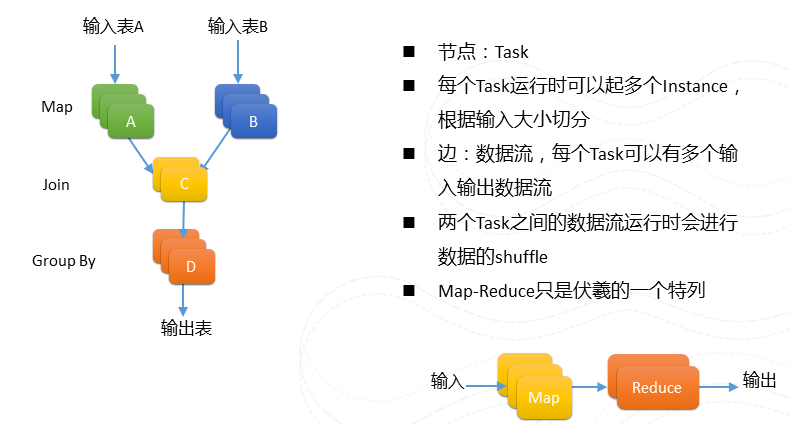
图8 DAG
讲完调度问题,在讲计算平台之前大概简单介绍一下我们作业的编程模型。有别于Map-Reduce把运算分为Map和reduce两个阶段,我们作业可以被描述为一个的DAG图。每个节点可以有多路的输入和输出。例如左图。
MaxCompute(原ODPS)分布式海量数据计算引擎
有了存储,有了资源调度。让用户来裸写DAG图来进行计算还是太难。所以我们需要搭建一个计算引擎来帮助数据工程师更加好的,更加容易的来做数据分析。这个计算引擎我们希望达到海量的高性能的计算能力,同时有完善安全的体制,有统一应用的编程框架,能够让我们上面的数据工程师更好更方便的开发数据应用,我们需要有稳定性、因为稳定是服务的第一要素。
统一的计算引擎
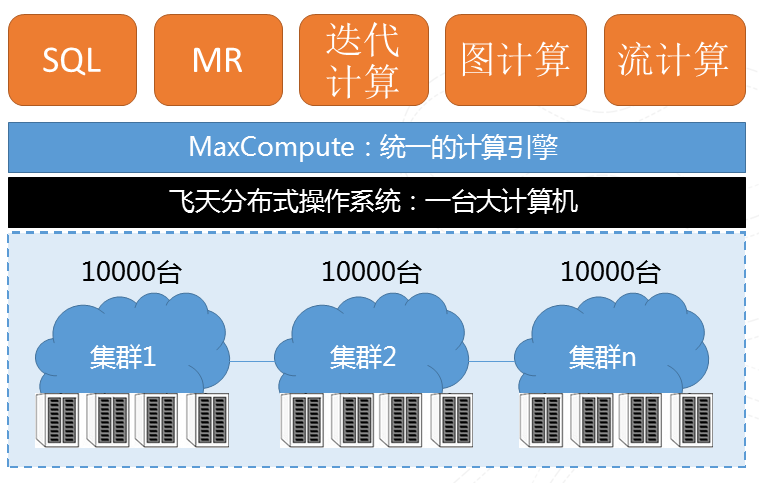
图9 计算基本架构
我们有多个万台以上的物理集群分布在多地的,在此基础上会有一个飞天的分布式操作系,再上面会搭建一个统一的计算引擎帮助我们的开发者迅速的进行开发。 之上我们提供了很多种运算方式,比如传统的SQL、MR、迭代计算、图计算、流计算等种种计算模式帮助开发人员解决现实问题。这个平台最主要有两个特点,第一是“大”,去年双十一6小时处理了100PB的数据;第二是“快”,去年打破世界纪录,100TB数据排序377秒。
MaxCompute系统架构
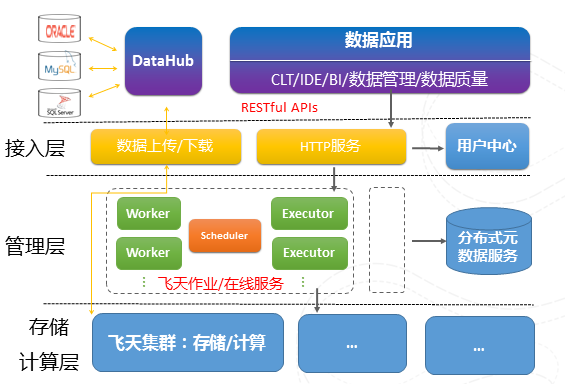
图10 MaxCompute系统架构
上图揭示了MaxCompute平台的体系结构,数据通过DataHub接入到计算引擎,不同于其他的计算分布式系统,我们还分割管理层和运算层,管理层封装底层多个计算集群,使得计算引擎可以当成一个运算平台,可以打破地域的限制,做到真正的跨地域、跨机房的大型运算平台,还有一个重要原因是基于安全性的要求。我们只在计算集群内去执行用户自定义的函数,而在管理层我们进行用户权限检查,在利用沙箱技术隔离恶意用户代码的同时,通过网段隔离,进一步保障用户数据的安全性。
数据从某种意义上是阿里的生命线,所以我们系统设计的时候就非常强调数据的管理,我们有很详尽的数据血缘关系的分析,分析数据之间的相关性。丰富的数据发现工具帮助数据工程师理解和使用数据等等。阿里也非常强调数据的质量,因为提高了系统中的数据质量将大大提高数据分析的效率,使得我们数据处理变得事半功倍。我们建立完整数据质量监控闭环,记录计算平台本身中各种运行数据的和各种元数据,这些数据其实本身就是非常巨大, 我们正好利用自己平台本身的强大数据分析能力来分析这些数据,通过系统已有的监控能力等等来提高自己上数据质量。
回归到运算,刚刚讲到我们在统一的计算引擎上面很多种计算模式,因为时间有限,我们就只用一个简单的例子来解释一下整个SQL的过程。
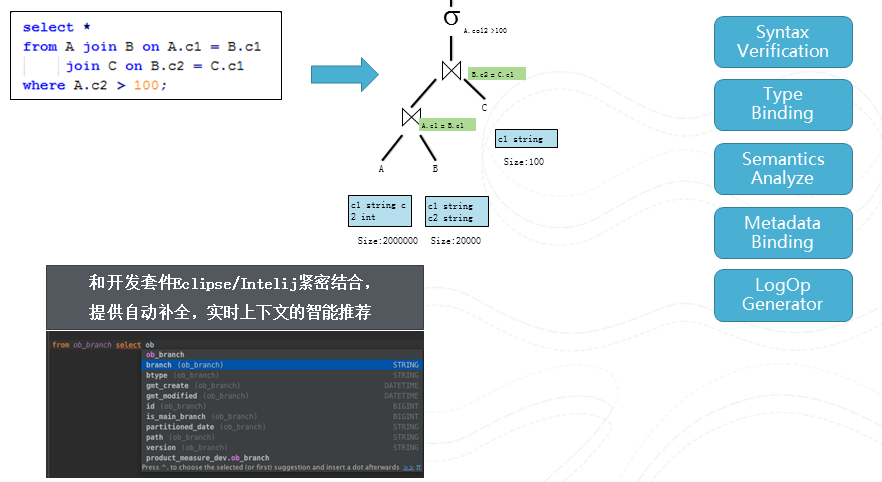
图11 编译
这个例子很简单,就是将A,B,C做个join后进行fliter后返回。编译器将该查询转变一个语法树,然后对该树进行多次的visit. 将不同的信息附加到该树上。我们将编译器和IDE紧密结合,在编辑查询的同时不停的进行编译,从而能够提供自动补全,上下文智能推荐等等visual studio的编程体验。
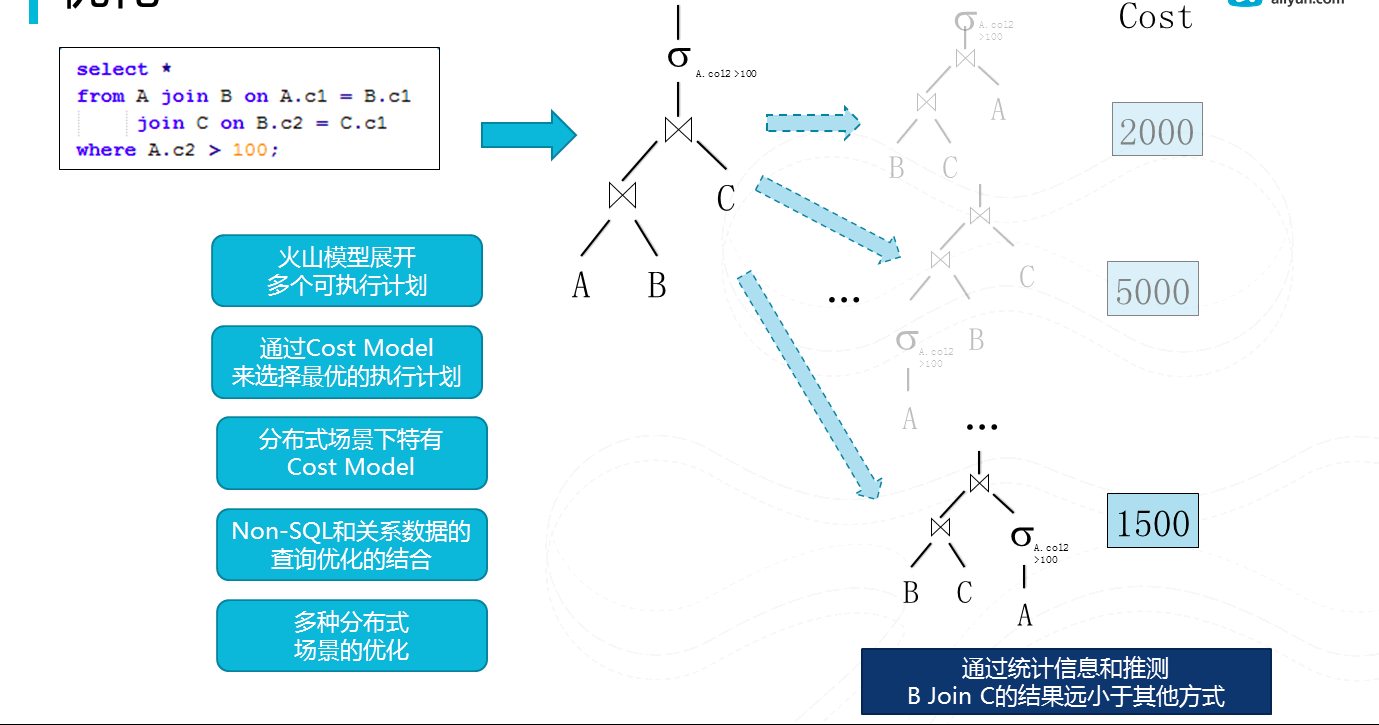
图12优化
经过编译,我们将生成一个逻辑执行计划,接下来我们将其进行优化来生成一个物理执行计划。我们采用cascading优化模型。就是将逻辑执行计划,利用变换规则把其分裂出多个等价的物理执行计划,然后通过一个统一的cost model来选择一个最优的执行计划(cost最低),现在开源社区也在从简单的rule-based像这种更加先进的cost-based的优化器演进。有别于单机成熟的数据库产品中的已经广泛使用cascading优化器。在分布式系统下,cost model本身, 大量用户自定义函数和分布式场景都带来不同的问题场景。
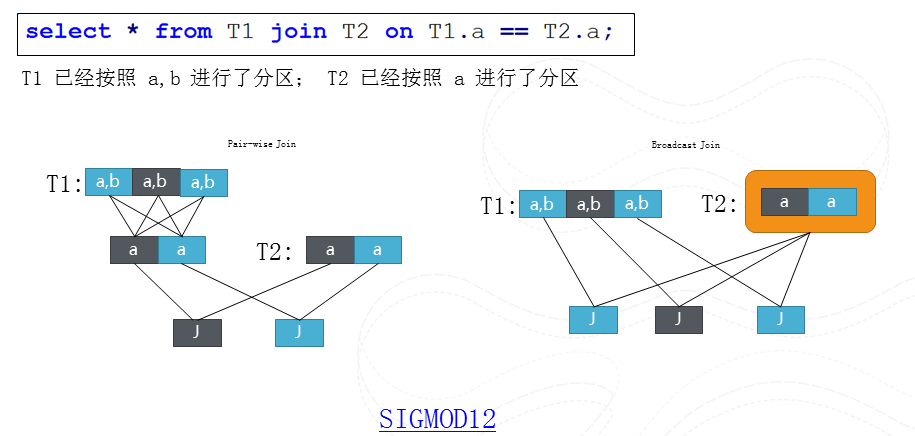
图13 分布式查询中的一个优化问题
这里就举一个例子来解释下分布式系统下的查询优化一个问题。我们需要T1和T2两个表格在
a column上做join,T1按照a, b进行分片, T2按照a进行分片。所以我们可以把T1重新按照a进行重新分片然后和T2进行join, 我们也可以把T2作为整体然后broadcast到T1的每个分片。这两个执行孰优孰劣取决于重新分片T1带来多余一个步骤重,还是broadcast T2带来多余数据拷贝重。如果这个分片是Range分片,我们还会有更多有趣的执行计划,大家可以去阅读我在SIGMOD 12上的论文。
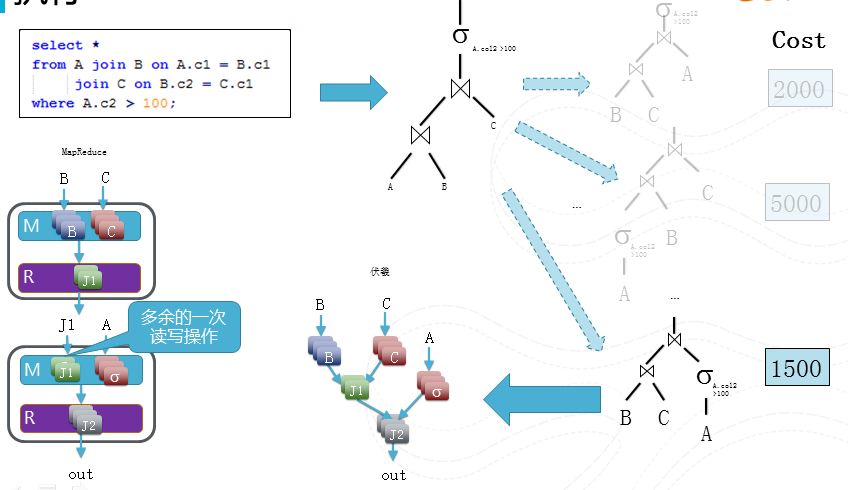
图14 执行
有了物理执行计划,我们将会把这个计划翻译为伏羲的一个作业区调度,因为伏羲作业可以描述DAG, 对比于常规的Map-Reduce,所以我们在这个例子中能够节省一次多余的读写操作。
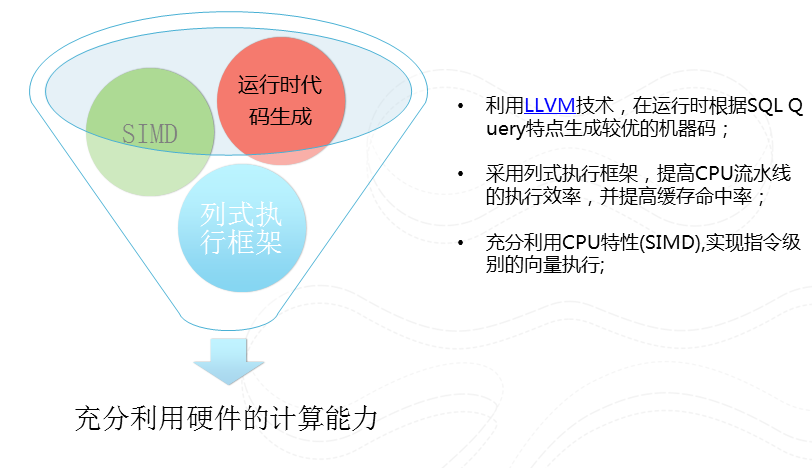
图15 更高效的执行引擎
我们在每个worker中执行的程序是经过根据该查询经过代码生成,然后经过LLVM编译器生成的高效的机器代码。我们采用列式执行,充分利用CPU本身向量执行指令来提高CPU流水线执行效率,并提高缓存的命中率。
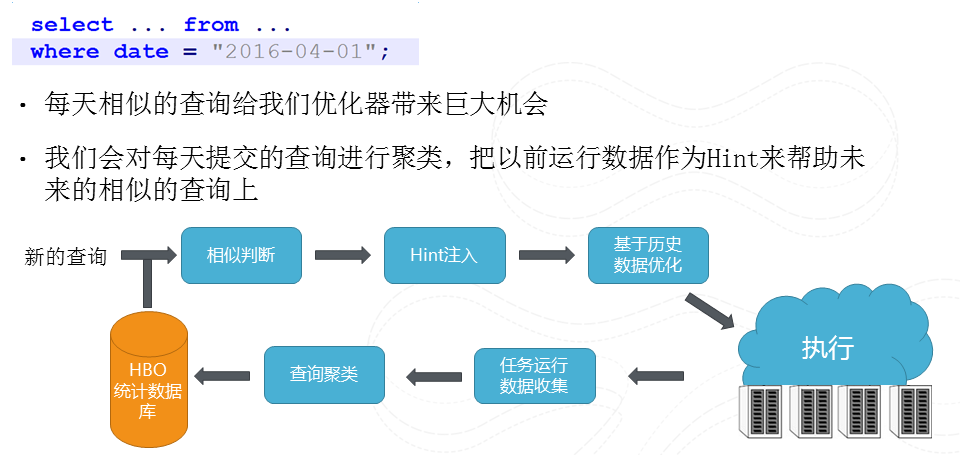
图16 HBO(基于历史的优化)
我们有大量相似查询,他们仅仅在处理数据时间上不同。所以我们可以利用数据分析的手段将这些相似的查询进行聚类,然后把原来以前执行得到的统计信息来帮助进行优化,这样我们就能够对用户自定义函数有了一些大致判断从而提高优化的结果
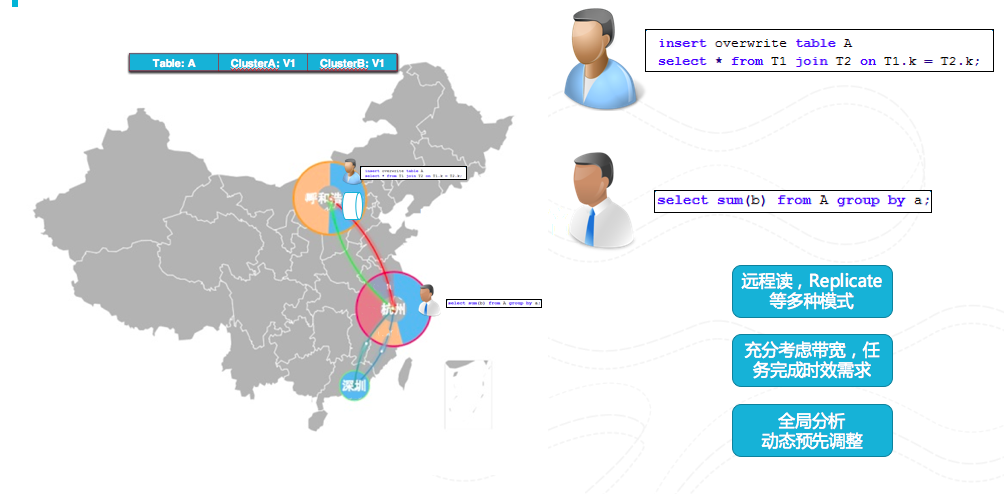
图17 全局调度
MaxCompute的管理层封装了多个计算集群从而做到打破机房限制,做到多地域的计算平台。再考虑任务完成时效要求,多集群之间的带宽大小等因素下进行全局分析,利用动态预先调整,远程读,复制等多种手段做到全局调度。
总结一下MaxCompute的特点,首先是大规模,万台单机群有跨集群的能力;兼容Hive语言;高性能,有列存储, 向量运算,C++代码运行,高运行效率,更好的查询优化;有稳定性,在阿里巴巴有5年的实践经验;有丰富UDF扩展,能够支持多种运行状态等等。讲讲大数据平台最新的进展,在刚刚做的基础上面会继续做的工作:会增强伏羲DAG,描述能力进一步增强,支持迭代计算、条件式的结束条件等,在MaxCompute平台继续加强优化,会做更多扩展,做更多性能上和成本上的优化;会贴近需求做更多迭代计算满足机器学习的算法特性等。
关于:中科研拓
深圳市中科研拓科技有限公司专注提供软件外包、app开发、智能硬件开发、O2O电商平台、手机应用程序、大数据系统、物联网项目等开发外包服务,十年研发经验,上百成功案例,中科院软件外包合作企业。通过IT技术实现创造客户和社会的价值,致力于为用户提供很好的软件解决方案。联系电话400-0316-532,邮箱sales@zhongkerd.com,网址www.zhongkerd.com
- 上一篇 [返回首页] [打印] [返回上页] 下一篇