专业 靠谱 的软件外包伙伴
百分点个性化系统系统软件开发架构详解
- 2016-10-14 16:29:19
-
百分点个性化系统开始于2009年,是百分点公司的第一个产品,也是一直延续至今的产品。个性化系统以电商推荐为切入点,涵盖电商、媒体、阅读、应用市场等领域,以第三方技术服务的形式为企业提供个性化推荐服务。个性化系统的几个重要特性百分点个性化系统致力于解决电商个性化的问题。我们先来看一下“个性化”问题的定义:
 对于如何定义个性化收益函数,一般有以下几方面的考虑:以KPI为导向:对于推荐效果考察的具体指标是什么?是点击率还是转化率,还是用户客单价,等等这些指标可以确定我们推荐优化的目标。根据业务需求定义:在实际推荐运营中,还会需要考虑商家的业务目标,比如追求高毛利,比如清库存,这时就要提高高毛利商品和库存商品的曝光率。根据业务效果修正:推荐是一个长期运营的活,对于推荐产生的效果需要能及时反馈到推荐系统中,形成动态反馈和修正的机制。连接现实业务和技术实现:推荐始终是服务于业务的,脱离了业务的推荐毫无意义,个性化系统就是要将业务需求转化为技术实现,最大程度自动化和智能化。在个性化系统中,还会面临以下技术和业务的挑战:数据稀疏是推荐系统中常见的问题,我们采用引入一些新的召回机制如文本相似性等非行为相关的召回制补充用户行为的不足。冷启动的问题,百分点本身可以汇集所有客户的上的用户行,一家新的客户接进来后,一般有30%-40%的用户是和百分点本身的用户库是重合的,对于全新的用户,可以在第一次着陆到首页采用一些大众化的推荐,当用户有进一步的行为便可以根据行为进行新的推荐了。我们大部分的算法都是实时处理的,所以真正冷启动的比例很小。大数据处理与增量计算,百分点大概有5000万的日活,1.5亿的pv,每天的推荐次数近2亿次,每天约1T的数据增量,对于所有组件必须能处理大量的数据,所以整体的架构以分布式和实时增量计算为主。多样性与精确性,推荐除了要考虑准确的召回,同时也要兼顾用户体验,避免推荐结果的单一化,也需要增加一些多样性的考虑。用户行为模式的挖掘和利用,用本质上说,推荐就是在做用户行为模工挖掘,找出用户的行为特征,给出相应的预测,这里面涉及到大量的算法和工程问题。多维数据的交叉利用,除了线上数据,不少客户有自己其他渠道的数据,这些数据也可以引入推荐系统,提升推荐的效果。效果评估,一套完整的推荐系统,必须一套完整的评估体系,百分点对每个推荐栏位都有详细的效果评估,除了推荐栏维度的点击率、转化率,还有商品维度和用户维度的相关评估指标。百分点的商业模式是做线上的电商导购员,媒体网站的导航员,提供个性化的用户体验,以百分点为数据中心,形成全网的用户行为偏好,利用大数据获得更精准的推荐。百分点如何实现个性化推荐系统?一个推荐系统的实施,大概要经历以下步骤:数据采集:我们主要会采集客户两方案的数据,Item的信息和User的行为,Item尽量覆盖多的属性维度,User行为尽量覆盖客户的所有业务流程。数据处理:数据采集上来后,经过不同算法的处理形成不同的结果数据,及时更新到内存数据库。推荐反馈:对于用户的每一次推荐请求,推荐服务会整合不同的算法和规则,在毫秒返回结果列表。在数据采集上,主要有两方面的技术:用户标识技术:除了cookie技术,还有硬件标识技术,精确的用户拉通和模糊的用户拉通技术,来支持跨浏览器到跨设备用户识别,其中基于GBDT的模糊拉通技术已经达到95%的准确度。数据获取技术:包括js埋点、sdk埋点、抓取、接口传输等,其中sdk的动态埋点技术可以实现app无升级的埋点更新,抓取系统的模版化也可以快速适应不同网站和网站改版情况下的抓取需求。在数据处理上,百分点也经历了从单机到主从再到全面分布式的架构变化,目前以kafka/storm/IMDB/Hadoop实现主要的计算和数据处理。在推荐算法:主要用到的用协同过滤、关联规则、统计等,在自然语言处理上,使用了分词、索引、主题词和舆情相关的算法、同时还有基于时间序列的预测,使用了GBDT+LR的排序框架。在推荐服务上,我们经历了固定算法->动态参数->规则引擎的三个阶段。在最初的推荐系统中我们直接将算法的结果做为推荐的结果返回,形成如看过还看过,买过还买过,经常一起购买等算法;在实际业务中,发现仅仅是推荐算法是不够的,算法的结果少怎么办,业务的条件限制怎么办,逐渐增加了动态参数来控制结果的返回;但这仍然不能很好的解决业务问题,如同一页面新老用户使用不同的算法,业务需要不能推荐赠品,需要考虑相同品类或不同品类优先的策略,业务的需求逐渐催生了规则引擎的诞生。规则引擎这里要重点介绍一下规则引擎,前面说了那边多算法和业务,规则引擎的出现才真正解决业务的问题:
对于如何定义个性化收益函数,一般有以下几方面的考虑:以KPI为导向:对于推荐效果考察的具体指标是什么?是点击率还是转化率,还是用户客单价,等等这些指标可以确定我们推荐优化的目标。根据业务需求定义:在实际推荐运营中,还会需要考虑商家的业务目标,比如追求高毛利,比如清库存,这时就要提高高毛利商品和库存商品的曝光率。根据业务效果修正:推荐是一个长期运营的活,对于推荐产生的效果需要能及时反馈到推荐系统中,形成动态反馈和修正的机制。连接现实业务和技术实现:推荐始终是服务于业务的,脱离了业务的推荐毫无意义,个性化系统就是要将业务需求转化为技术实现,最大程度自动化和智能化。在个性化系统中,还会面临以下技术和业务的挑战:数据稀疏是推荐系统中常见的问题,我们采用引入一些新的召回机制如文本相似性等非行为相关的召回制补充用户行为的不足。冷启动的问题,百分点本身可以汇集所有客户的上的用户行,一家新的客户接进来后,一般有30%-40%的用户是和百分点本身的用户库是重合的,对于全新的用户,可以在第一次着陆到首页采用一些大众化的推荐,当用户有进一步的行为便可以根据行为进行新的推荐了。我们大部分的算法都是实时处理的,所以真正冷启动的比例很小。大数据处理与增量计算,百分点大概有5000万的日活,1.5亿的pv,每天的推荐次数近2亿次,每天约1T的数据增量,对于所有组件必须能处理大量的数据,所以整体的架构以分布式和实时增量计算为主。多样性与精确性,推荐除了要考虑准确的召回,同时也要兼顾用户体验,避免推荐结果的单一化,也需要增加一些多样性的考虑。用户行为模式的挖掘和利用,用本质上说,推荐就是在做用户行为模工挖掘,找出用户的行为特征,给出相应的预测,这里面涉及到大量的算法和工程问题。多维数据的交叉利用,除了线上数据,不少客户有自己其他渠道的数据,这些数据也可以引入推荐系统,提升推荐的效果。效果评估,一套完整的推荐系统,必须一套完整的评估体系,百分点对每个推荐栏位都有详细的效果评估,除了推荐栏维度的点击率、转化率,还有商品维度和用户维度的相关评估指标。百分点的商业模式是做线上的电商导购员,媒体网站的导航员,提供个性化的用户体验,以百分点为数据中心,形成全网的用户行为偏好,利用大数据获得更精准的推荐。百分点如何实现个性化推荐系统?一个推荐系统的实施,大概要经历以下步骤:数据采集:我们主要会采集客户两方案的数据,Item的信息和User的行为,Item尽量覆盖多的属性维度,User行为尽量覆盖客户的所有业务流程。数据处理:数据采集上来后,经过不同算法的处理形成不同的结果数据,及时更新到内存数据库。推荐反馈:对于用户的每一次推荐请求,推荐服务会整合不同的算法和规则,在毫秒返回结果列表。在数据采集上,主要有两方面的技术:用户标识技术:除了cookie技术,还有硬件标识技术,精确的用户拉通和模糊的用户拉通技术,来支持跨浏览器到跨设备用户识别,其中基于GBDT的模糊拉通技术已经达到95%的准确度。数据获取技术:包括js埋点、sdk埋点、抓取、接口传输等,其中sdk的动态埋点技术可以实现app无升级的埋点更新,抓取系统的模版化也可以快速适应不同网站和网站改版情况下的抓取需求。在数据处理上,百分点也经历了从单机到主从再到全面分布式的架构变化,目前以kafka/storm/IMDB/Hadoop实现主要的计算和数据处理。在推荐算法:主要用到的用协同过滤、关联规则、统计等,在自然语言处理上,使用了分词、索引、主题词和舆情相关的算法、同时还有基于时间序列的预测,使用了GBDT+LR的排序框架。在推荐服务上,我们经历了固定算法->动态参数->规则引擎的三个阶段。在最初的推荐系统中我们直接将算法的结果做为推荐的结果返回,形成如看过还看过,买过还买过,经常一起购买等算法;在实际业务中,发现仅仅是推荐算法是不够的,算法的结果少怎么办,业务的条件限制怎么办,逐渐增加了动态参数来控制结果的返回;但这仍然不能很好的解决业务问题,如同一页面新老用户使用不同的算法,业务需要不能推荐赠品,需要考虑相同品类或不同品类优先的策略,业务的需求逐渐催生了规则引擎的诞生。规则引擎这里要重点介绍一下规则引擎,前面说了那边多算法和业务,规则引擎的出现才真正解决业务的问题: 在实际使用中我们在一个推荐栏位中会用到类似于下面的规则:
在实际使用中我们在一个推荐栏位中会用到类似于下面的规则: 在百分点的规则库中有将过100个规则模块,这些模块像搭积木一样进行不同的组合拼装,满足业务需求的同时解决个性化的问题。我们现在也对这个规则语言做了可视化,业务人员可以像画流程图一样进行拖拽来完成规则的编写。百分点推荐系统实践架构至此,百分点推荐引擎的核心架构图如下:
在百分点的规则库中有将过100个规则模块,这些模块像搭积木一样进行不同的组合拼装,满足业务需求的同时解决个性化的问题。我们现在也对这个规则语言做了可视化,业务人员可以像画流程图一样进行拖拽来完成规则的编写。百分点推荐系统实践架构至此,百分点推荐引擎的核心架构图如下: 推荐引擎主要由场景、规则、算法和展示这四部分组成。场景引擎就像是侦察兵,探察用户处理什么状态,是无目的闲逛还是有购物目标,有什么样的偏好;规则引擎就像是司令部,根据用户的状态制定相应的规则;算法引擎是后勤部队,为系统提供各种不同的算法结果;展示引擎是先头部队,以最能打动客户的形式将结果展现在用户面前。个性化系统的架构介绍完推荐引擎的核心,我们再来看整个个性化系统的架构。
推荐引擎主要由场景、规则、算法和展示这四部分组成。场景引擎就像是侦察兵,探察用户处理什么状态,是无目的闲逛还是有购物目标,有什么样的偏好;规则引擎就像是司令部,根据用户的状态制定相应的规则;算法引擎是后勤部队,为系统提供各种不同的算法结果;展示引擎是先头部队,以最能打动客户的形式将结果展现在用户面前。个性化系统的架构介绍完推荐引擎的核心,我们再来看整个个性化系统的架构。 整个系统以nginx前端集群对外提供服务,通过数据采集服务进入系统,分布式的消息队列连接后后端的实时处理和离线处理框架,底层存储方式使用了多种存储技术支持不同的应用场景。整个系统以zookeeper作为配置客理的中心,配以集群运行状态的监控保障整个系统的稳定运行。
整个系统以nginx前端集群对外提供服务,通过数据采集服务进入系统,分布式的消息队列连接后后端的实时处理和离线处理框架,底层存储方式使用了多种存储技术支持不同的应用场景。整个系统以zookeeper作为配置客理的中心,配以集群运行状态的监控保障整个系统的稳定运行。 整个实时推荐的架构以分布式、高可用、高性通、高泛化为目标,以大规模、实时性、内存计算为解决方案,构建快速响应的推荐架构。
整个实时推荐的架构以分布式、高可用、高性通、高泛化为目标,以大规模、实时性、内存计算为解决方案,构建快速响应的推荐架构。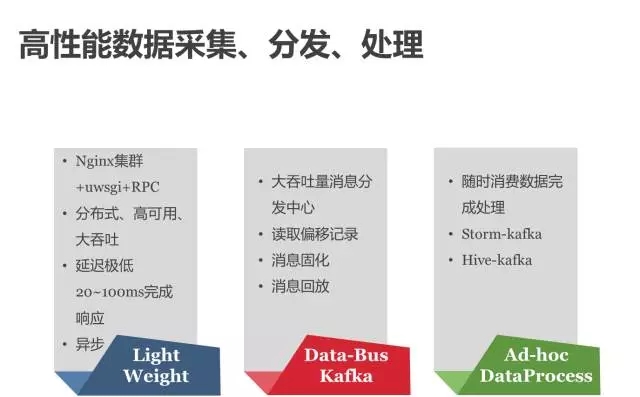 在实践过程中,百分点也正在经历由SaaS到PaaS的发展历程,推荐引擎提供云端的数据服务,而实际上Everything is DataFlow! 一切皆数据流! Bigdata time comes。在大数据时代,推荐引擎也只是大数据平台的一个应用。离线计算平台百分点离线计算平台,基于大数据的应用构建架构,是以Hadoop为基础的大数据技术生态:
在实践过程中,百分点也正在经历由SaaS到PaaS的发展历程,推荐引擎提供云端的数据服务,而实际上Everything is DataFlow! 一切皆数据流! Bigdata time comes。在大数据时代,推荐引擎也只是大数据平台的一个应用。离线计算平台百分点离线计算平台,基于大数据的应用构建架构,是以Hadoop为基础的大数据技术生态:
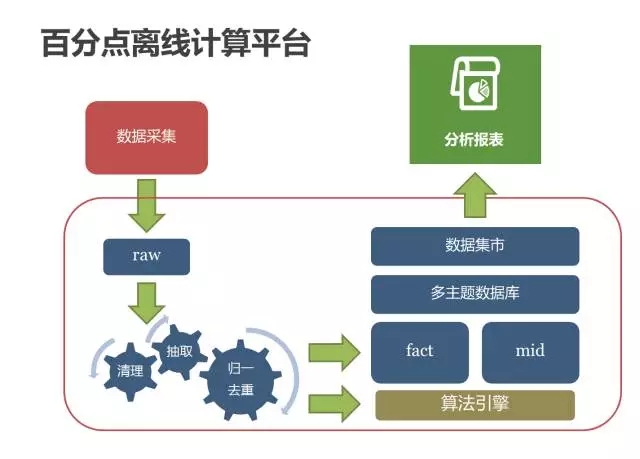 离线计算平台主要服务于数据分析、离线特征工程、模型训练等工作。在线上的推荐服务中,百分点实时计算平台发挥着更大的作用。实时计算平台
离线计算平台主要服务于数据分析、离线特征工程、模型训练等工作。在线上的推荐服务中,百分点实时计算平台发挥着更大的作用。实时计算平台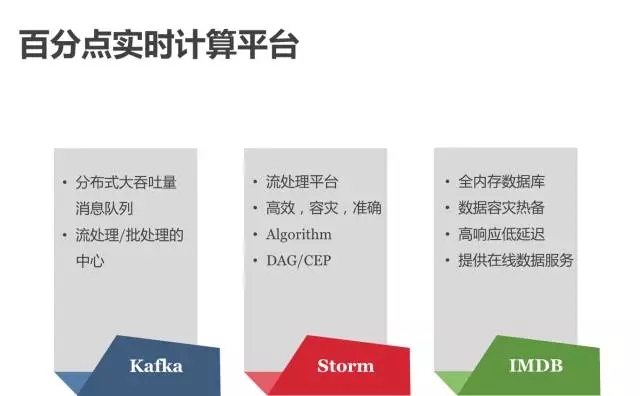
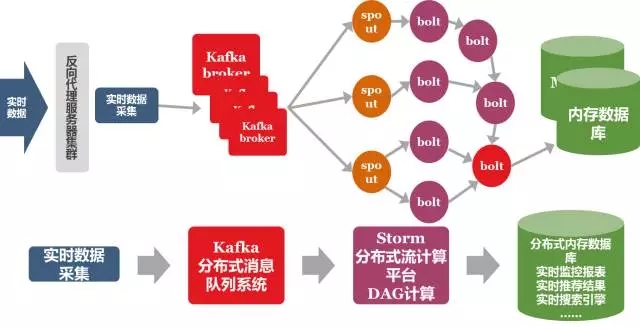 在实时计算平台上,我们构建了实时计算应用:proxima计算框架
在实时计算平台上,我们构建了实时计算应用:proxima计算框架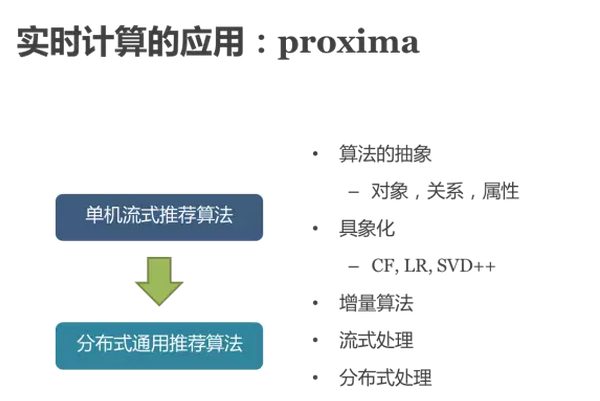 以协同过滤为例,以结点和关系来抽象,通过结点之间的消息传递来实现算法的计算,proxima上实现协同过滤的示意图如下:
以协同过滤为例,以结点和关系来抽象,通过结点之间的消息传递来实现算法的计算,proxima上实现协同过滤的示意图如下: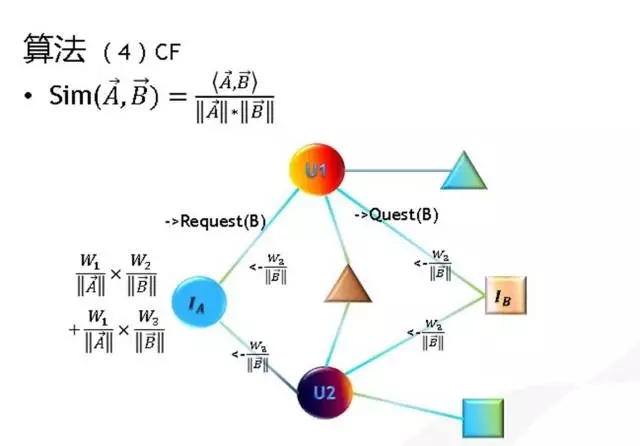 实时计算的另一个应用是实时的推荐效果监测:
实时计算的另一个应用是实时的推荐效果监测: 搜索平台下面介绍一下推荐的好朋友:搜索平台
搜索平台下面介绍一下推荐的好朋友:搜索平台 百分点的搜索平台基于solr构建,架构图如下:
百分点的搜索平台基于solr构建,架构图如下: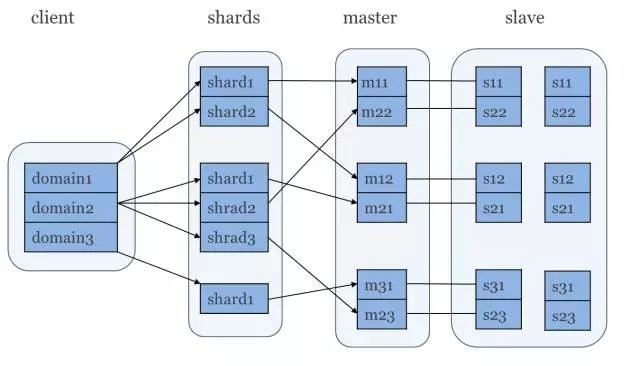 对于不同的客户域,我们采用了分片的技术,同时使用不同的master和slave的划分,来实现负载的平衡,利用读写分离解决索引更新和查询的速度问题。
对于不同的客户域,我们采用了分片的技术,同时使用不同的master和slave的划分,来实现负载的平衡,利用读写分离解决索引更新和查询的速度问题。
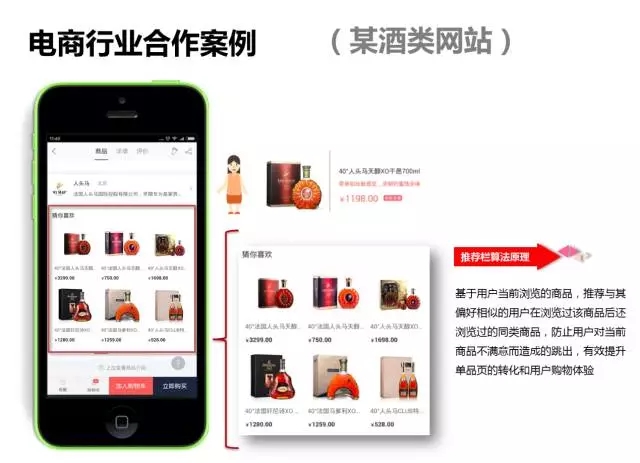
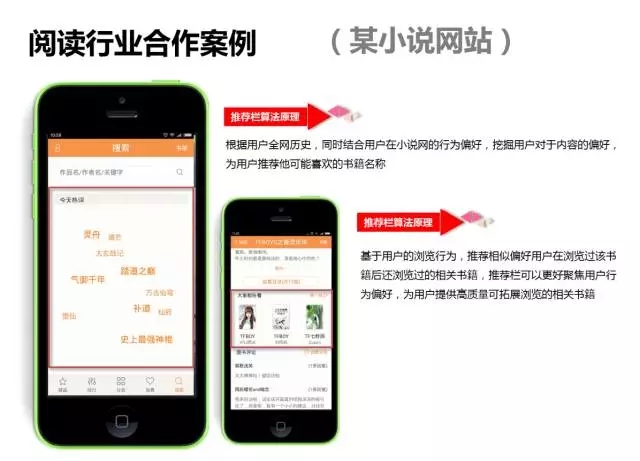
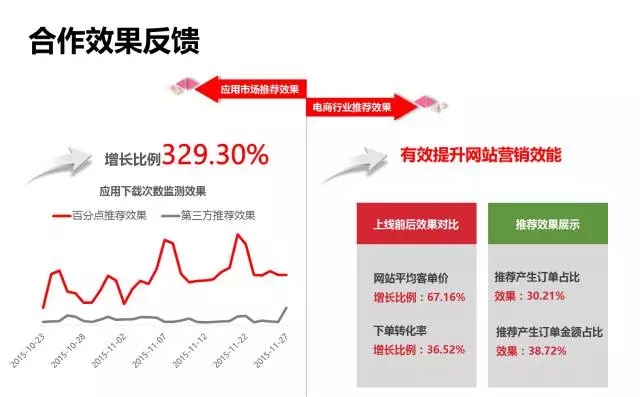
 搜索做为推荐算法补充,在很多推荐的场景都发挥了重要作用。个性化系统行业应用案例架构介绍到此为止,接下来介绍一下百分点个性化系统在一些行业的应用案例:
搜索做为推荐算法补充,在很多推荐的场景都发挥了重要作用。个性化系统行业应用案例架构介绍到此为止,接下来介绍一下百分点个性化系统在一些行业的应用案例:
关于:中科研拓
深圳市中科研拓科技有限公司专注提供软件外包、app开发、智能硬件开发、O2O电商平台、手机应用程序、大数据系统、物联网项目等开发外包服务,十年研发经验,上百成功案例,中科院软件外包合作企业。通过IT技术实现创造客户和社会的价值,致力于为用户提供很好的软件解决方案。联系电话400-0316-532,邮箱sales@zhongkerd.com,网址www.zhongkerd.com
- 上一篇 [返回首页] [打印] [返回上页] 下一篇