网易视频云OpenStack监控系统平台架构
- 2016-04-18 12:51:12
-
网易视频云是网易倾力打造的一款基于云计算的分布式多媒体处理集群和专业音视频技术,为客户提供稳定流畅、低时延、高并发的视频直播、录制、存储、转码及点播等音视频的PASS服务。在线教育、远程医疗、娱乐秀场、在线金融等各行业及企业用户只需经过简单的开发即可打造在线音视频平台。现在,网易视频云的技术专家与大家分享一下如何监控 OpenStack。
OpenStack 是开源 IaaS 解决方案,组件众多,架构复杂,并且技术栈长。随着系统规模不断扩大, 如何快速发现,定位故障,最终处理故障成了一个急需解决的问题。OpenStack 的监控分为三方面:监控、报警;诊断、追踪;故障处理;其中监控和报警是发现问题的第一步,解决的主要问题是在大规模部署 OpenStack 的情况下,如何准确、详尽地报告系统目前情况,及早发现并提示故障发生。
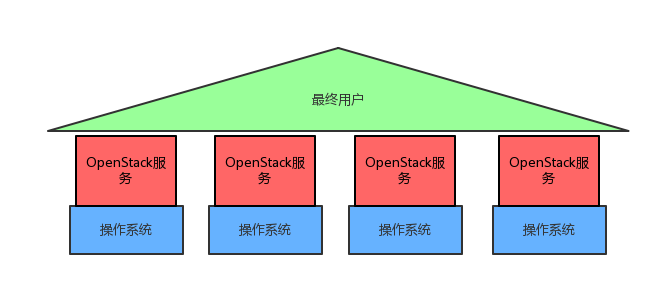
OpenStack 的监控可以分为三个层次:操作系统监控,服务监控,端到端监控;层层依赖,服务的稳定依赖操作系统的稳定,而只有服务稳定了,用户才能正常的操作云资源。他们的关系如下图所示:
-
端到端的监控着眼于发现影响用户的问题,这类问题优先级很高,但是由于属于最高层,具体产生的原因不很明显,所以需要下面两层的监控发现更细致的问题。
-
服务监控着重从 OpenStack 的软件架构,实现原理出发,站在运维人员的视角,判断服务是否正常。
-
操作系统监控收集操作系统的基本指标,如果操作系统异常,在其上运行的服务软件很难正常工作。在一般大型互联网公司中这一层的监控由 SA 负责。
选择开源系统
开源监控系统千千万,如 zabbix,nagios,Cacti,Munin,icinga,ganglia ,collectd + graphite,influxed + grafana,prometheus 等等。但是 OpenStack 的特殊性决定了我们需要一款监控系统:
-
监控系统目前状况,在超出预期时报警;
-
记录历史信息,比如过去一年的 CPU 使用情况,内存使用情况,因为运维 OpenStack 系统的关键是预测和判断系统的承载能力,运维人员需要有历史数据;
-
图形化,数据可视化是运维 OpenStack 的关键,运维人员需要在系统还没有达到承载上限的时候预判风险,提前扩容;
-
故障响应可扩展:发现问题除了报警,对于能够自动化处理的故障,监控系统能够支持自动化处理;
-
报警管理,问题分轻重缓急,轻度的问题可以推迟处理后者不处理,严重的需要立刻报警;
开源系统在以上几个方面各有所偏重,使用方法也各不相同,本文主要基于 zabbix 设计 OpenStack 的监控系统,不过基本思路可以应用到任何监控系统上。
1. 操作系统监控
操作系统是整个 OpenStack 的基础,选择通用的监控项即可,主要监控如下信息:
监控内容 磁盘空间使用率 磁盘io使用率 CPU 使用率 内存使用率 网卡使用率 每一个 OpenStack 节点都必须监控操作系统状态。在 zabbix 中可以设置一个 Template_OS_Openstack,所有 host 都关联到这个 template 上。
2. 服务监控
OpenStack 的服务繁杂,架构比较复杂, 比较容易出问题的也是这一层。按照实现原理和使用的技术,可以将服务分为3类:基础软件(如 haproxy,memcache,mysql等);API 类服务(nova-api,cinder-api,glance-api);RPC 类服务(nova-compute,neutron-agent,cinder-volume);按照不同服务设计不同的监控方法。
系统中,不同节点会安装不同的服务,比如控制节点一般会安装 API 类服务和基础软件,计算节点会安装 RPC 类服务,但不能排除异常情况,由于突发情况,在计算节点上安装了 API 类服务临时扩展 API 性能。所以 zabbix 中应该对不同的服务设置对应的 template。比如安装了 nova-compute 软件的 host 应该关联到 Template_App_Nova_compute,其中仅包含了 nova-compute 的监控项。
2.1 基础软件
软件 监控项 Haproxy 监控各个端口是否正常服务;各个端口连接数;内存占用情况,CPU 占用情况; MySQL 内存占用情况;CPU占用情况;监控端口是否正常连接; Memcache 监控 11211 端口是否正常服务;监控 eviction 值; Libvirt 监控服务是否正常响应请求; open-vswitch 监控服务是否存在并且是否正常相应请求;另外也可以使用 sflow 协议来网络流量。 RabbitMQ 监控服务是否存在;内存使用情况;磁盘使用情况,连接数;队列消费者数量;队列残余消息数 NOS 监控能否正常连接; 2.2 API 类服务
API 类服务又细分为两类,一类只提供 API 服务且连接消息队列,转发请求给 RPC 服务。另一类仅提供 API 服务。 第一类服务有:nova-api-os-compute,cinder-api,neutron-server。这类服务监控进程是否存在(check_proc),监控 HTTP 端口是否正常提供服务(check_http),是否正常连接消息队列 check_proc_mq(如果没有连接消息队列进程很可能已经block)。 第二类服务有:glance-api,glance-registry,keystone,nova-api-metadata,neutron-metadata-agent。这类服务只需监控进程是否存 (check_proc) 在以及 HTTP 端口是否正常提供服务 ( check_http) 即可。
2.3 RPC 类服务
RPC 类服务主要监控进程是否存在(check_proc),以及日志是否正常滚动(check_log)。如果发现日志长时间(1天)没有发生滚动,可以认为进程已经 block。 为了精确的判断 RPC 类服务是否正常,可以用程序模拟 RPC 请求,如果服务正常相应则判断服务正常,否则异常(check_rpc)。 具体实现方法可以在 nova-manage 新加一个命令,用户发送探测 RPC 请求给特定的服务,cinder,neutron,ceilometer 等服务也类似。这样不仅复用了项目代码中的配置文件解析逻辑和 RPC 框架,功能是非能聚,而且不会将消息队列密码等敏感信息暴露在监控系统中。
2.4 监控项总结
软件 监控项 nova-api-os-compute check_proc, check_http, check_proc_mq nova-api-metadata check_proc, check_http nova-compute check_proc, check_proc_mq , check_log nova-conductor check_proc, check_proc_mq nova-consoleauth check_proc nova-consoleproxy check_proc nova-scheduler check_proc, check_rpc, check_log neutron-server check_proc, check_rpc, check_log neutron-l3-agent check_proc, check_log neutron-ovs-agent check_proc, check_log neutron-dhcp-agent check_proc, check_log neutron-monitor check_proc, check_log glance-api check_proc, check_http glance-registry check_proc, check_http cinder-api check_proc, check_http, check_proc_mq cinder-scheduler check_proc, check_rpc, check_log cinder-volume check_proc, check_rpc, check_log 3 端到端监控
端到端监控通过模拟用户行为,确保用户能够正常访问系统。一个分布式系统中的组件往往是冗余的,某些节点故障,或者某个服务故障可能并不会影响到用户。并且,即使所有服务监控都显示正常,仍可能因为程序 bug 导致用户无法正常访问系统。 端到端的监控可以通过自动化测试用例来模拟,比如 tempest 或者 rally。因为 OpenStack 是 SOA 的架构,测试用例完全覆盖了用户所有可能的请求,所以完全可以选取关键用例且对系统影响较小的 case,定时测试系统整体情况。一方面能比用户更早发现问题,同时记录下的历史记录也能反应出系统的运行情况。
为了系统的安全性,可以专门创建一个配额有限的用户,配置 tempest 或者 rally 使用。
基本的用例需要包括:
用例 参考耗时 Get token 10 s List flavor 20 s List image 20 s LIst instance 20 s List absolute limit 20 s List snapshot 20 s List volume 20 s List image using glance 10 s List networks 20s Create instance 200s Create instance, create snapshot, create instance from snapshot 400 s Create volume and boot instance from it 350 s Create volume and attach it to instance 350 s check network connectivity 300s Create keypair 25 s Create security group 25 s Check network parameters 50 s
关于:中科研拓
深圳市中科研拓科技有限公司专注提供软件外包、app开发、智能硬件开发、O2O电商平台、手机应用程序、大数据系统、物联网项目等开发外包服务,十年研发经验,上百成功案例,中科院软件外包合作企业。通过IT技术实现创造客户和社会的价值,致力于为用户提供很好的软件解决方案。联系电话400-0316-532,邮箱sales@zhongkerd.com,网址www.zhongkerd.com
-
- 上一篇 [返回首页] [打印] [返回上页] 下一篇